 |
CORIS/CODIS
Progettazione e costruzione di un CORpus
di Italiano Scritto
|
1.
Ai fini di una breve descrizione della
realizzazione del CORIS, le fasi principali si possono indicare come:
1. progettazione
a) tipologia del corpus
b) dimensione
c) rappresentatività
2. elaborazione del modello di costruzione
a) identificazione della popolazione
b) definizione dei criteri di selezione
3. definizione della strutturazione
a) articolazione dei componenti
b) definizione dei rapporti fra i componenti
c) campionamento
4. definizione
5. reperimento e inserimento dei materiali
6. lemmatizzazione e annotazione grammaticale
2.1
Ai fini della progettazione e della costruzione del CORIS alcune scelte
sono state preliminari, ponendo la base per le operazioni successive.
In primo luogo si è trattato di definire la
finalità del progetto e la tipologia del corpus
che si intendeva costruire.
Fin dalle prime fasi della progettazione, si è identificata
la finalità del lavoro nella costruzione di un corpus
generale, per la cui descrizione si poteva ancora fare
riferimento alla definizione data del Brown Corpus, uno dei primi corpora
elettronici. Come il Brown Corpus era stato indicato quale "a standard
sample of present-day English for use with digital computers",
così per il CORIS, nella fase di progettazione, la
finalità poteva identificarsi nella costituzione di un
insieme di testi informatici rappresentativi, in senso lato,
dell'italiano attuale. Nell'identificazione di tale finalità
trovava risposta uno dei primi problemi che si ponevano nella
progettazione del corpus, la scelta da operare fra
dimensione sincronica e diacronica. La selezione dei testi doveva avere
luogo a livello sincronico per consentire, tramite generalizzazione,
una descrizione dell'italiano ricorrente nell'uso comune.
Maggiori problemi poneva la scelta fra lingua scritta e lingua parlata.
Considerate varie opzioni, pur negli evidenti vantaggi presentati da un
corpus costituito sia da testi parlati
che da testi scritti, si è deciso di procedere, in questa
fase della ricerca, dando la preferenza ai testi scritti. La decisione
si è basata su criteri esterni ed interni. In primo luogo
è stata determinata dal panorama linguistico italiano e
dalla collocazione che il corpus sarebbe venuto ad
assumere, affiancandosi a opere quali il Lessico di frequenza
dell'italiano parlato (LIP,1993), il Lessico
di frequenza della lingua italiana contemporanea (LIF,1972),
il Vocabolario elettronico della lingua italiana. Il
vocabolario del 2000 (VELI,1989), il Corpus di
italiano parlato (Cresti 2000) e la Letteratura
Italiana Zanichelli in cd-rom (LIZ,
1993¹, 1995² e 1997³), per indicare le
più significative realizzazioni editoriali. Vanno menzionati
inoltre l'Italian Reference Corpus (1991) e l'Italian
Corpus Documentation PAROLE (1998) sviluppati presso
l’ILC del CNR di Pisa.
In secondo luogo, si è ritenuto
preferibile, considerando le trasformazioni che le nuove tecnologie
stanno operando nelle modalità comunicative, non porre il
problema dei rapporti fra la lingua tradizionalmente indicata come
parlato canonico e le estensioni tecnologiche che di questa si
realizzano attraverso il mezzo telefonico, radiofonico, televisivo e/o
informatico.
Si è quindi scelto di costruire un corpus
sincronico di lingua scritta, i cui
testi costitutivi si collocano, pur con qualche approssimazione, in un
periodo configurato negli anni '80 e '90 (con una maggiore estensione
temporale per la narrativa) ed appartengono all'italiano che, nei
termini posti da Nencioni (1983), può essere definito
"scritto-scritto".
2.2
Maggiore considerazione ha richiesto la definizione della dimensione
del CORIS. Ad un esame dei corpora
attualmente disponibili è emerso con chiarezza come non si
potesse fare riferimento ad una dimensione standardizzata. Lo sviluppo
rapido ed esteso che ha caratterizzato, specie negli ultimi anni, sia
l'accessibilità a basso costo dell'hardware
sia la produzione di programmi software sempre
più efficienti e di facile utilizzo, ha profondamente mutato
i criteri sottesi alla costituzione dei corpora più
recenti rispetto a quelli di prima o seconda generazione.
Se le scelte sottese ai corpora di prima
generazione, come il Brown Corpus, potevano essere state determinate
prioritariamente dalla potenzialità delle tecnologie
informatiche, le tecnologie attuali non pongono limiti alle scelte
dello studioso, che può estendere la dimensione di un corpus
fino ad includere le varietà considerate rilevanti ai fini
dell'analisi e, all'interno di queste, operare un'adeguata selezione
dei testi rappresentativi. Gli sviluppi della tecnologia informatica
che si sono avuti negli ultimi decenni, l'attuale velocità
nell'elaborazione del materiale ed il basso costo delle
unità di memorizzione consentono oggi di porre il traguardo
oltre le otto cifre, offrendo la possibilità di costruire
corpora di centinaia di milioni di parole come il British
National Corpus e la Bank of English. Sembra di potere affermare che,
particolarmente per quanto concerne la lingua scritta, lo standard di 1
milione di parole sia ormai sostituito da uno standard di 100 milioni.
Ogni generalizzazione, tuttavia, appare controvertibile,
così come la definizione di un traguardo obbligato. Il Brown
Corpus (1967), con 1 milione di parole, 500 campioni di testi scritti,
di 2000 parole ciascuno, rappresentativi di generi omogeneamente
rappresentati, è ancora considerato da numerosi studiosi un
valido modello. Ed uno dei corpora di lingua
inglese di più recente costituzione, il Longman Spoken and
Written English Corpus - LSWE Corpus - che vede la collaborazione di
studiosi come Biber, Johansson, Leech, Conrad e Finegan, presenta una
dimensione di circa 40.000.000 parole e contiene 37.244 testi. Testi,
si afferma, che variano nella loro lunghezza a seconda del registro.
Un ulteriore aspetto da tenere in considerazione nella definizione del corpus
è dato dall'introduzione dei corpora
di monitoraggio. Questi prevedono un costante aggiornamento tramite un
flusso di inserimento determinato da una periodica inserzione di dati
attraverso un insieme di filtri, che operano una selezione sia sui
nuovi dati sia su quelli già inseriti.
La configurazione che il corpus di
monitoraggio viene ad assumere fa sì che nella
definizione della dimensione di un corpus cadano
quegli aspetti di finitezza e di permanenza che sono stati
caratterizzanti negli ultimi decenni. Il corpus
assume una configurazione dinamica che appare tanto più
vantaggiosa e rilevante considerando che, con le nuove
possibilità date dallo sviluppo dei supporti informatici e
delle memorie, al momento attuale non occorre più procedere
all'operazione di selezione e di scarto dei testi già
inseriti. Appare possibile gestire allo stesso tempo un corpus
definito nelle sue componenti principali e un corpus
di monitoraggio, aperto, in grado di registrare le innovazioni e le
modifiche ricorrenti nell'uso. La combinazione consente di potere
accedere ad un corpus disponibile in una forma
finita - sia questa data in rete o da CD-Rom - suscettibile degli
aggiornamenti forniti dal monitoraggio, così come
dell'introduzione di sottocorpora supplementari rappresentativi di
ulteriori varietà.
Si è ritenuto quindi di potere procedere alla progettazione
di un corpus la cui dimensione, pur essendo
configurata come "ampia", non è stata predeterminata ma
posta in relazione alla selezione delle varietà linguistiche
considerate rappresentative e, in quanto tale, collocata come obiettivo
di una fase intermedia della ricerca, successiva alla compilazione di
un corpus pilota.
2.3
La definizione della rappresentatività costituisce
un momento cruciale nella costruzione di un corpus, ma risulta uno
degli aspetti maggiormente controversi fra gli specialisti, in
particolare per l'ambiguità che si riscontra nell'uso,
dovuta all'intrecciarsi della connotazione quantitativa e qualitativa.
Se per alcuni studiosi l'estensione dei corpora a
centinaia di milioni di parole può compensare una scarsa
differenziazione delle varietà rappresentate, per altri
un'ampia differenziazione delle varietà è posta
come condizione essenziale di ogni operazione di generalizzazione. Per
quanto ci concerne, già nelle prima fasi del lavoro abbiamo
ritenuto che il problema della rappresentatività non cadeva
con le possibilità di ampliamento del corpus,
ma anzi poteva venire da questo enfatizzato.
Nonostante l' estensione della dimensione a centinaia di milioni di
parole, ogni corpus rappresenta un campione limitato della lingua in
uso. Un'operazione di campionamento, per quanto estesa, risulta
inevitabilmente semplificata rispetto alla complessità del
fenomeno in esame. Pur incorporando selezioni probabilistiche nella
costruzione del corpus, ci è apparso che
nel passaggio dal campione alla generalizzazione fosse opportuno
prevedere un'approssimazione per gradi che consentisse il massimo di
flessibilità e di dinamicità al modello proposto.
Date le difficoltà, vorrei dire di ordine epistemologico,
riscontrate nella progettazione di un corpus che
potesse incontestabilmente definirsi rappresentativo di una lingua o di
uno stato di una lingua, si è ritenuto di procedere
riconoscendo i limiti insiti nella progettazione stessa ed
identificando parametri che potessero giungere a controbilanciare quei
limiti. Si sono quindi definiti alcuni criteri di identificazione dei
parametri di riferimento che consentissero la costituzione di un
insieme di sottocorpora in cui fossero incluse,
rappresentate ed adeguatamente bilanciate le principali varietà
dell'italiano scritto e, allo stesso tempo, si è configurata
la possibilià di giungere all'elaborazione di un modello di
costruzione dinamico e adattivo, tale da rispondere alle esigenze ed
alle ipotesi di lavoro dei diversi studiosi senza venire meno ai
criteri costitutivi del corpus.
3.
Nell'ambito della linguistica dei corpora
è posto come criterio fondamentale, recepito in tutti i
progetti e le ricerche, che i testi costitutivi siano autentici e
ricorrenti nella comunicazione sociale. Non così comunemente
accettata appare la scelta dei testi da inserire, in particolare non
appare oggetto di una scelta comunemente accettata se i testi siano da
inserirsi nella loro interezza, o in frammenti che si possano definire
rappresentativi. Si tratta di un punto nodale, che nella progettazione
ha costituito l'oggetto di approfondite riflessioni.
Come si è visto, nei primi corpora, come
il Brown, si è operato una standardizzazione dei campioni.
L'uniformità dimensionale dei testi è posta come
principio costitutivo.Se disaccordo vi è stato, questo si
è incentrato sulla dimensione dei
campioni. Nell'elaborazione del modello di costruzione
si è ritenuto che, nelle condizioni attualmente create dai
programmi software, il problema non sia dato dalla
definizione della dimensione del campione, ma
piuttosto dalla scelta che deve essere operata fra
testi e frammenti di testi. La prima porta inevitabilmente alla
mancanza di standardizzazione dei campioni testuali. Si dà
raramente il caso che più testi, siano essi giornalistici,
narrativi o scientifici, contengano lo stesso numero di parole. La
seconda, d'altro lato, può comportare una più
forte presenza della soggettività del ricercatore ed implica
una decontestualizzazione delle sequenze selezionate che potrebbe
portare, nell'ampia dimensione prevista, ad invalidare la
rappresentatività stessa del corpus. Si è quindi
proceduto privilegiando l'inserimento dei testi nella loro
totalità rispetto alla standardizzazione della dimensione
dei campioni.
In un momento successivo, si è proceduto alla definizione
delle varietà linguistiche costitutive del corpus
visto come una collezione di documenti identificabili per caratteri
esterni ed interni, in cui la singolarità della
varietà viene a sfumare rispetto alla massa dei dati. Questo
ha costituito un punto importante. Pur inserendo nel corpus aree
specialistiche, quali il linguaggio burocratico-amministrativo,
giuridico, scientifico, si è cercato di fare confluire non
una raccolta di testi specialistici, ma una varietà di
tipologie che si collocano, secondo la nostra indagine, su un continuum,
sovrapponendosi ed integrandosi.
3.1
Nella definizione dei criteri di selezione e di costruzione
si è fatto riferimento a criteri esterni ed interni,
privilegiando i criteri esterni per ridurre al minimo l'intervento del
ricercatore. Inoltre, considerando il contesto scientifico in cui il
CORIS viene a collocarsi così come l'avanzata estensione e
disseminazione di corpora, costruiti o in
costruzione, che si riscontra a livello internazionale, si è
introdotto un ulteriore criterio, "la comparabilità", per
non sottovalutare le possibiltà che vengono offerte allo
studioso dalla comparazione interlinguistica dei corpora.
Ai fini della definizione di un primo livello di articolazione del corpus,
una pregnanza cruciale hanno assunto criteri che definirei di
testualità esterna e di comparabilità. Questi
hanno portato a configurare un primo livello di articolazione
- dato dai sottocorpora - in cui, riducendo al
minimo le scelte soggettive del ricercatore, si potesse fare
riferimento al alcune macro-varietà
identificate sulla base dell'aspetto esteriore o degli elementi
materiali dei testi, evidenti nella loro caratterizzazione ed
agevolmente comparabili.
Considerata troppo ampia una distinzione che venisse operata fra testi
"pubblicati" e "non pubblicati", si è proceduto selezionando
le varie forme di pubblicazioni date dalla "stampa", dalla "narrativa",
da vari tipi di volumi e di saggi identificabili nella loro
varietà come "miscellanea" e sussumendo in una sezione
definita "ephemera" i vari testi a mano, a stampa e, principalmente, in
formato elettronico, caratterizzati dalla loro breve permanenza.
Definite queste macro-varietà, si è ritenuto di
dovere operare un secondo livello di articolazione -
dato dalle sezioni e ulteriormente scomponibile in sottosezioni
- che, ancora basato su parametri esterni, consentisse tuttavia di
contestualizzare i dati reperiti. E’ apparso chiaro, ad
esempio, che non si poteva procedere ad un campionamento della
popolazione "stampa" se non in considerazione di una seconda
articolazione, connessa alla realtà socio-culturale
nazionale. Questo è stato considerato un momento necessario
per giungere a definire, anche se con una certa approssimazione, i
componenti della popolazione.
Il riferimento ai parametri indicati ha portato a
configurare la seguente strutturazione
| sottocorpus |
STAMPA |
| sezioni |
quotidiana, periodica, supplementi |
| sottosezioni |
nazionale,
locale
specialistica, non specialistica
connotata, non connotata |
| sottocorpus |
NARRATIVA |
| sezioni |
romanzi,
racconti |
| sottosezioni |
italiana,
straniera,
per adulti, per ragazzi
poliziesca, di avventure, di fantascienza, delle donne |
Altre varietà potranno essere inserite
in una seconda fase del lavoro all'interno di supplementary
corpora.
4.
Definiti i criteri di selezione, si è proceduto alla pianificazione
dei sottocorpora, prendendo in primo luogo in esame la dimensione
che questi dovevano assumere ed i rapporti che le
dimensioni dei vari sottocorpora e delle sezioni dovevano presentare.
In una prima ipotesi si era considerata la
possibilità di procedere sulla base di una selezione
randomizzata e di correlare la dimensione di ogni sottoinsieme di testi
al numero, anche approssimato, dei destinatari di quei testi. Una tale
disamina è risultata eccessivamente circoscritta nel
privilegiare parametri quantitativi - quali la tiratura e la diffusione
- rispetto a parametri qualitativi - quali il tempo e le
modalità di utilizzazione dei testi in esame o il livello di
attenzione cognitiva. Pur nella difficoltà presentata
dall'introduzione di parametri qualitativi, e quindi non misurabili, si
è ritenuto che il solo dato quantitativo non fosse
sufficientemente significativo e che dovesse essere integrato, nella
definizione dei rapporti percentuali fra i sottocorpora e le sezioni,
da variabili di tipo qualitativo al fine di non sopravvalutare alcune
varietà rispetto ad altre. Questa scelta procedurale
è stata corroborata da un'analisi di tipo puntuale riferita
all'anno 1997:
| STAMPA
(dati FIEG, La stampa in Italia
1995-1998, Milano, 1999)
|
LIBRI
(dati AIE, La produzione libraria
italiana del 1997, Milano, 1999)
|
| Quotidiani
2 955 501 360
Settimanali 730
364 544
Mensili 194
607 972
|
Fiction
119 100 000
Non-fiction 179 400 000
|
| TOTALE
3 880 473 876 |
TOTALE
298 500 000 |
Il rapporto 1:12 approssimativamente identificabile fra i testi propri
della comunicazione di massa ed i testi del mercato librario non poteva
essere accettato come riproducibile nel campione. D'altro lato, esso
appariva di tale rilevanza da non potere essere trascurato nemmeno ai
fini della comparabilità del corpus in costruzione.
All'interno dei rapporti consentiti dai volumi di
vendita - rapporti che, sulla base dei dati, sono rappresentati come un
intervallo di valore - si è convenuto di fissare i rapporti
fra le varie fasce di circolazione prendendo, nell'intervallo dei
rapporti consentito, il valore che più privilegia i testi di
circolazione più bassa per non penalizzare alcune
varietà quale, ad esempio, quella data dai testi epistolari.
Scelto un ampio insieme di varietà
linguistiche, si sono predisposti i documenti per l'inserimento nei
singoli sottocorpora e, per aderire ai criteri di
rappresentatività, si è proceduto ad una
selezione randomizzata dei testi nell'ambito di ogni singolo
sottocorpus. Ritenendo di operare in una situazione sufficientemente
oggettiva, si è configurata una strutturazione del corpus
basata sulla seguente articolazione delle macro-varietà
precedentemente identificate:
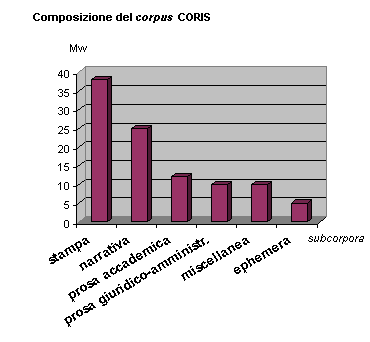
STAMPA 38%
NARRATIVA 25%
PROSA ACCADEMICA 12%
PROSA GIURIDICO-AMMINISTRATIVA 10%
MISCELLANEA 10%
EPHEMERA 5%
5.
Un corpus di italiano scritto - un
modello definito ed un modello dinamico
Il corpus di italiano scritto - CORIS - risulta
definito nelle sue generalità :
una raccolta di testi, autentici e ricorrenti
nell'uso, in formato elettronico, selezionati come rappresentativi
dell'italiano attuale
così come nella dimensione:
corpus generale costituito da 100 milioni di
parole aggiornato tramite un corpus di monitoraggio
inglobato con cadenza biennale.
Il CORIS è stato progettato e costruito
come un corpus generale di riferimento per l'analisi dell'italiano
scritto e sarà messo in linea entro settembre 2001. Il CORIS
si presenta allo studioso come immediatamente fruibile.
Allo stesso tempo, considerato il ruolo cruciale che viene ad assumere
la comparabilità in un corpus di riferimento, si
è ritenuto fosse opportuno prevedere la
possibilità di elaborare una strutturazione alternativa del
corpus che lo rendesse adattabile alle esigenze dei diversi
ricercatori. Accanto al CORIS - COrpus di
Riferimento dell'Italiano Scritto - si è configurato il CODIS
- COrpus Dinamico dell'Italiano Scritto. Finalizzato ad esigenze
particolari che possono emergere a livello di analisi interlinguistica,
il CODIS presenta una struttura dinamica ed adattiva che fornisce la
possibilità di escludere sottocorpora considerati non
pertinenti e quindi di procedere, ai fini di determinate procedure di
ricerca, ad una selezione di sottocorpora e, aspetto che vorrei
sottolineare, delle dimensioni che si ritiene che questi debbano
presentare. Il CODIS è predisposto ad essere dinamicamente
adattato a diverse situazioni comparative. Tramite procedure
sufficientemente semplici è data la possibilità
al singolo studioso, qualora lo questi lo ritenga opportuno, di
selezionare i sottocorpora considerati pertinenti e rilevanti
scegliendo la dimensione considerata maggiormente funzionale ai fini
della ricerca fra le quattro dimensioni indicate o combinandole per
costruire dimensioni intermedie.
|
Sottocorpus
|
Dimensioni
selezionabili (%)
|
| Stampa |
20
|
10
|
5
|
3
|
| Narrativa |
13
|
7
|
3
|
2
|
| Prosa accademica |
5
|
4
|
2
|
1
|
| Prosa giuridico-amm. |
4
|
3
|
2
|
1
|
| Miscellanea |
4
|
3
|
2
|
1
|
| Ephemera |
2
|
1
|
1
|
1
|
|
